Reference
HowToGuides
Manuals
LabAlumni
DataAnalysis
Advice for...
Admin
This is an old revision of the document!
~~DISCUSSION~~
![]() Under construction, do not use!
Under construction, do not use! ![]()
Goals:
Resources:
Systems for the acquisition of neural data give us a necessarily imperfect view of the brain. Some of these limitations are obvious, such as a finite number of recording sites and contamination of the data with movement artifacts and system noise. Other limitations are perhaps more subtle, and include the pitfalls associated with limited (temporal) sampling of the underlying process and the properties of specific recording systems.
An important phrase to remember in any data analysis workflow is "garbage in, garbage out." Making sure that your input is not garbage starts with a thorough understanding of the recorded signal and how it is stored. (Of course, if you abuse it enough, even the best data can rapidly turn to garbage. But that is beyond the scope of this module, which deals with the raw data.)
Before you begin, do a git pull from the course repository. Also, to reproduce the figures shown here, change the default font size (set(0,'DefaultAxesFontSize',18) – a good place to put this is in your path shortcut).
Let's start with an example that illustrates what can go wrong if you are not aware of some basic sampling theory ideas. To do so, we will first construct a 10Hz signal, sampled at 1000Hz. Recalling that the frequency f of a sine wave is given by $y = sin(2 \pi f t)$:
Fs1 = 1000; % Fs is the conventional variable name for sampling freq F1 = 10; twin = [0 1]; % use a 1-second time window (from 0 to 1s) tvec1 = twin(1):1/Fs1:twin(2); % timebase for signal signal1 = sin(2*pi*F1*tvec1);
Notice the general approach in defining time series data: we first construct a timebase (conventionally named tvec, or t) and then the signal.
☛ Plot the signal1 variable and verify that the result matches your expectation: for instance, it should have a specific number of peaks.
Let's say we are going to sample this signal at 12Hz:
Fs2 = 12; tvec2 = twin(1):1/Fs2:twin(2); signal2 = interp1(tvec1,signal1,tvec2,'nearest');
Note the use of the interp1() function. This is a very important and frequently used command with some interesting options we'll explore later. For now, we are telling it something like, “we have an input signal, specified by tvec1 and signal1; return those values of signal1 for those values of tvec1 closest to those in tvec2. An intuition for that is illustrated in the figure below – basically you want to get a value for some time (the red dot) that isn't explicitly present in your signal (the blue stems):
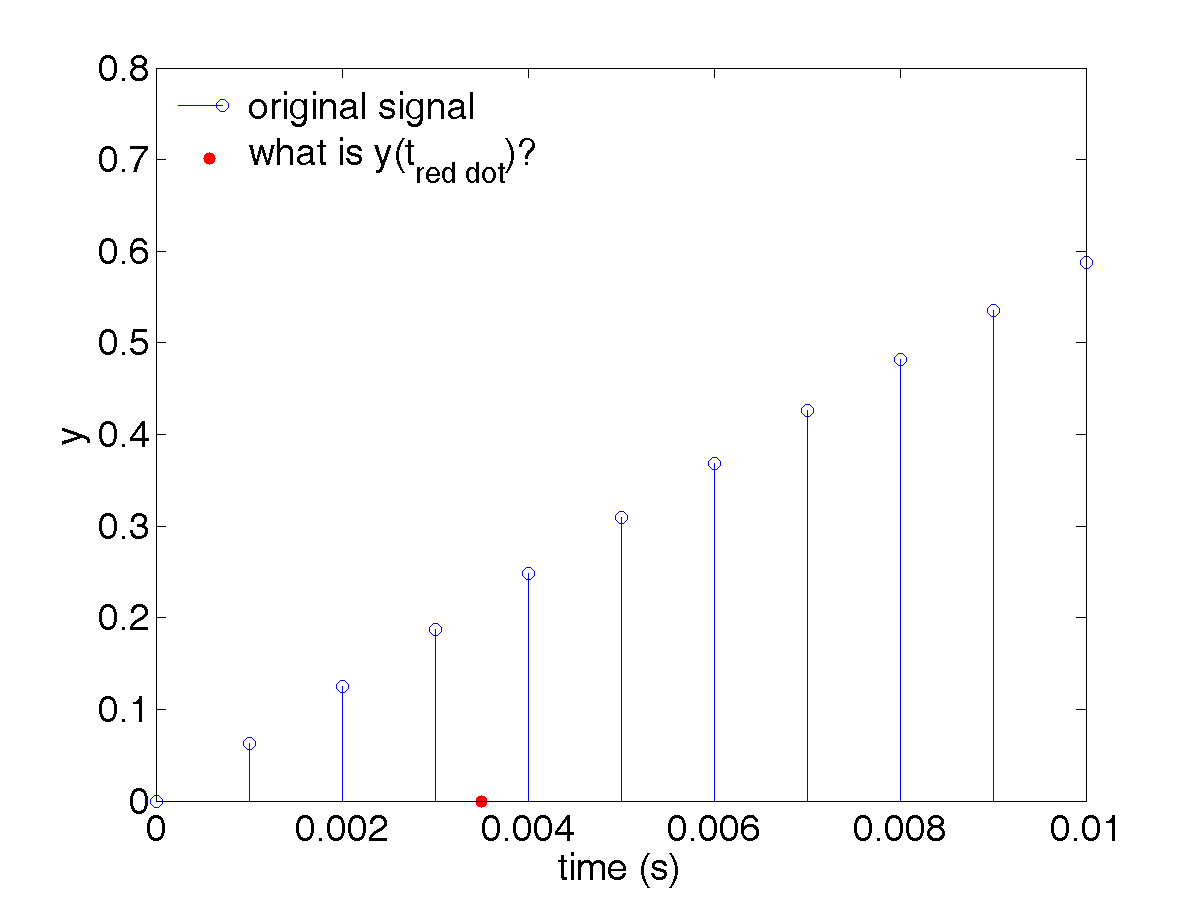
Now that we know how the signal2 variable – the signal we are seeing by sampling at 12 Hz – is obtained, we can plot it:
plot(tvec1,signal1); hold on; plot(tvec2,signal2,'.g','MarkerSize',20); plot(tvec1,-sin(2*pi*2*tvec1),'r--','LineWidth',2); xlabel('time (s)'); ylabel('y');
You should see:
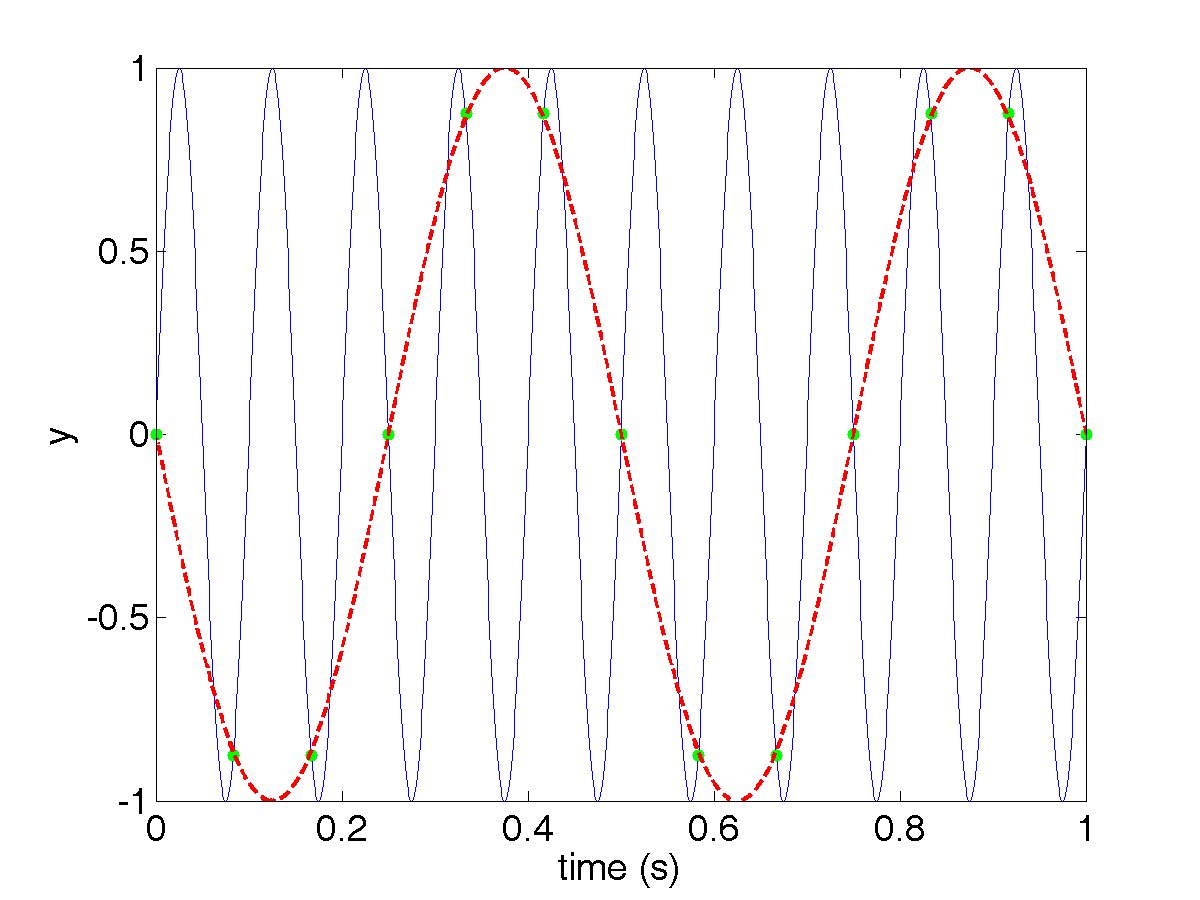
The individual data points we obtain with our 12Hz sampling are shown in green. Notice that it describes a periodic signal (red dashed line) with a frequency nothing like the 10Hz in the original signal (blue sine wave)! We might be tempted to conclude that we are seeing a 2Hz signal, when in fact there is no such thing in the original data. This effect is known as aliasing (i.e. the existence of multiple underlying signals which could produce a given set of samples), and it can happen when certain conditions are met, which we will explore next.
The Nyquist sampling theorem states that the minimum sampling frequency required to avoid aliasing is twice the frequency of the signal, i.e.
$$ F_s \geq 2*F_{orig} $$
This Nyquist criterion is intuitive, when you plot the signal that can be obtained by sampling our original signal at 20Hz, i.e. twice the frequency:

Note that we obtain a signal which is periodic (repeating) at 10Hz, as we know to be correct.
An important consequence of the Nyquist criterion is that
$$ F_{orig} \leq F_s / 2 $$
In other words, the highest-frequency signal that can be recovered when sampling is half the sampling frequency. This frequency is sometimes referred to as the Nyquist frequency or Nyquist limit (the precise terminology gets a bit confused, but in neuroscience they are interpreted as referring to the same thing). So, for instance, digital audio on CDs and most digital file formats is typically represented with Fs = 44100 Hz, which means that the highest frequency that theoretically can be reproduced is 22050 Hz, corresponding approximately to the upper limit of human hearing.
However, it is best not to cut things too fine: say you are interested in detecting a “gamma” frequency of 75Hz with your EEG recording system. If you acquire data at Fs = 150 Hz, you might run into problems.
☛ To see this, change Fs2 in the code above to 20, and plot the result. What do you see?
Thus, a (very safe) rule of thumb is to acquire data at a sampling frequency four times the minimum signal frequency you are interested in detecting.
In the real world, the frequency at which we can acquire data will be limited the properties of your experimental equipment. For instance, the maximum sampling rate on a typical Neuralynx system is 32 kHz. Thus, the highest-frequency signal we can detect is 16 kHz (the Nyquist frequency). Crucially, however, we cannot rule out the possibility that frequencies above 16 kHz are present in the signal we are sampling from! Thus, we risk aliasing: generating “phantom” frequencies in our sampled data that don't exist in the true signal. What to do?
The general solution is to apply an anti-aliasing filter to the data before sampling. To illustrate this, let's generate a signal consisting of two frequencies:
Fs1 = 1200; F1 = 3; F2 = 10; twin = [0 1]; tvec1 = twin(1):1/Fs1:twin(2); signal1a = sin(2*pi*F1*tvec1); signal1b = 0.5*sin(2*pi*F2*tvec1); signal1 = signal1a + signal1b;
Now, if we sample this signal at 12 Hz, by taking every 100th sample (note Fs is set to 1200), we will get aliasing due to the fact that our sampling frequency is less than twice that of the highest frequency in the signal (10 Hz):
dt = 100; tvec2 = tvec1(1:dt:end); signal2 = signal1(1:dt:end); % sample at 12 Hz - every 100th sample subplot(131) plot(tvec1,signal1); hold on; stem(tvec2,signal2,'.g','MarkerSize',20); title('without anti-aliasing filter');
As you can see in the resulting plot, the sampled data (green dots) isn't a clean 3Hz sine wave as we would hope to get – it is contaminated by an alias of the 10Hz component in the underlying signal. Thus, our naive sampling method of taking every 100th sample is dangerous! Here is how to do it properly:
% sample at 12 Hz with different method signal2d = decimate(signal1,dt); subplot(132) plot(tvec1,signal1a,'b--'); hold on; stem(tvec1d,signal2d,'.g','MarkerSize',20); xlabel('time (s)'); ylabel('y'); title('with anti-aliasing filter'); subplot(133) plot(tvec2,signal2-signal2d,'r','LineWidth',2); title('difference');
You should get:
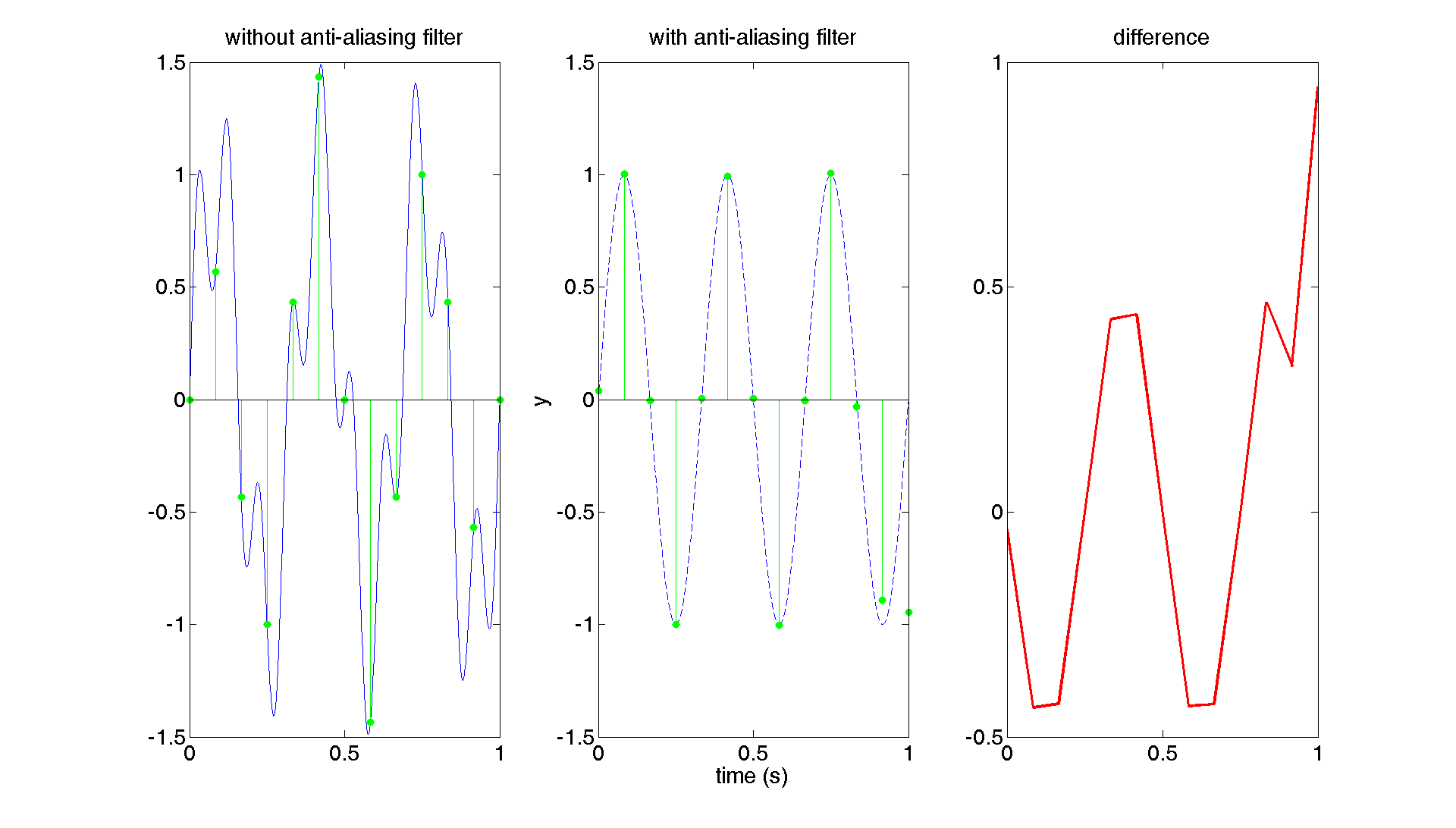
Note that after using decimate() instead of directly taking each 100th sample, we recover a relatively clean 3Hz sine (except for some edge effects; more on that in later modules). You can see the difference between the two sampling methods are substantial!
The way decimate() works is that it first applies a filter to the data, removing any frequencies that could cause aliases (i.e. anything with a frequency of at least half the new sampling frequency). We will explore filters in more detail in Module 6.
Data acquisition systems use the same principle. If you look in the settings of your system, you should be able to find the details of the filter applied to the data by default. It should have an upper cut-off frequency set to prevent aliasing. For instance, for some Neuralynx systems, all data above 9000 Hz is filtered out.
☛ Suppose you acquired some nice neural data at 2 kHz, and now you decide to analyze frequencies in the 50-100 Hz range. To speed up your analysis and save space, you want to downsample your data to 500 Hz: a good choice, more than adequately above the Nyquist frequency. What MATLAB command would you use to downsample this data, and why? (Hint: what is wrong with the downsample() function you may be tempted to use?)
You may have noticed that the sampled signals above often look a bit choppy, losing the smoothness of the originals. As discussed in the Leis book, we can try to recover the original using interpolation. Let's illustrate this by first constructing a 100 Hz signal, sampled at 2 kHz:
fs1 = 2000; tvec = 0:1/fs1:4; % construct time axis, sampled at 2kHz freq1 = 100; y = sin(2*pi*freq1*tvec); % 100Hz signal ax1 = subplot(211); stem(tvec,y); title('original');
Say we wish to subsample down to 500Hz to save space. Naively, we might simply take every 4th sample (in fact, this is what the MATLAB function downsample() does):
subsample_factor = 4; tvec2 = tvec(1:subsample_factor:end); % take every 4th sample y2 = y(1:subsample_factor:end); ax2 = subplot(212); stem(tvec2,y2,'r'); title('subsampled'); xlabel('time (s)');
☛ Why is it okay to subsample this way in this case?
It's hard to see what is going on when we are so zoomed out. Let's use the axes handles introduced last week to rectify this:
xl = [1 1.04]; linkaxes('x','ax1',ax2); set(ax1,'XLim',xl); % see what I did there?)
That's better. Notice that in the subsampled plot, you can detect the presence of the 100Hz signal by noticing that each sample repeats (has the same value) every 10ms. However, it doesn't look much like the original – as discussed in the Leis book, we can attempt to reconstruct it:
hold on; y_interp = interp1(tvec2,y2,tvec,'linear'); p1 = plot(tvec,y_interp,'b'); y_interp2 = interp1(tvec2,y2,tvec,'spline'); p2 = plot(tvec,y_interp2,'g'); legend([p1 p2],{'linear','spline'},'Location','Northeast'); legend boxoff
You should obtain something like:
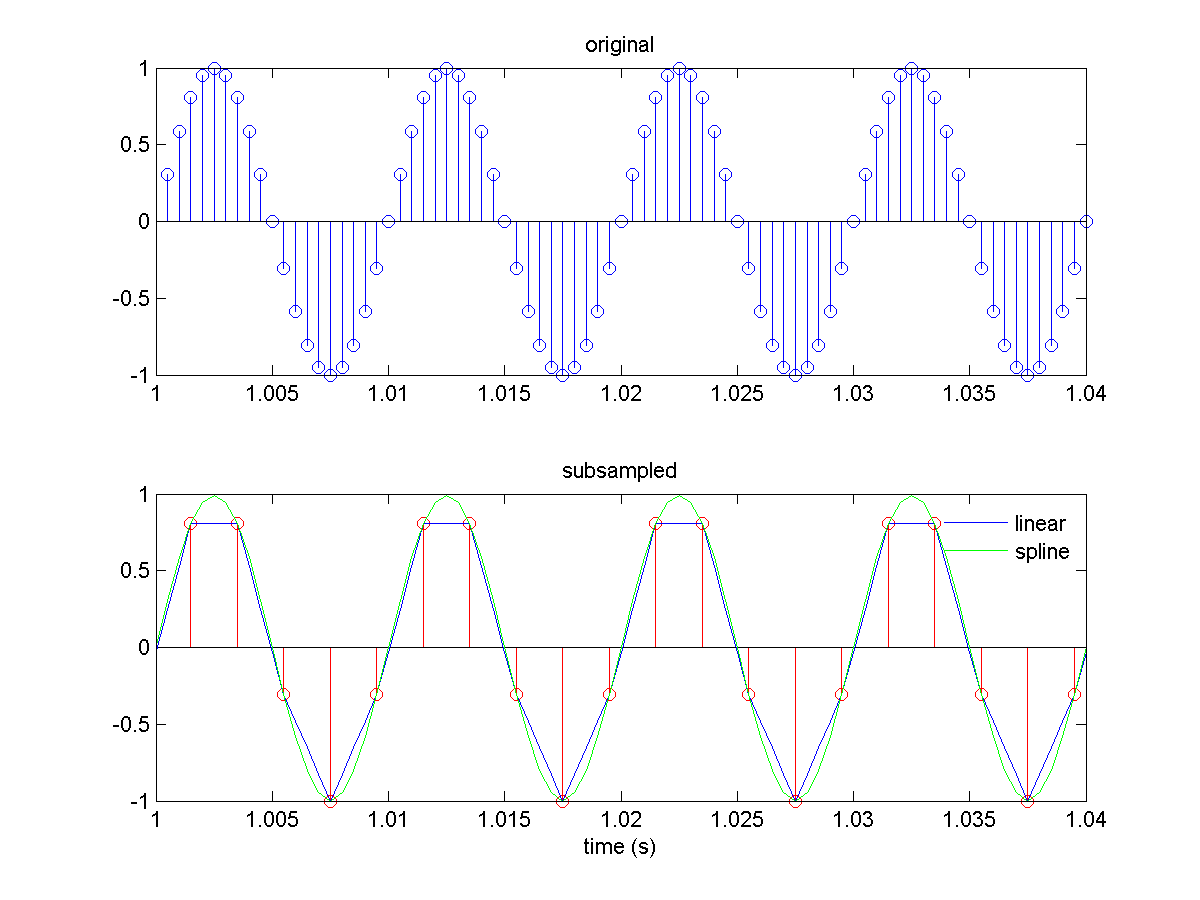
Notice how the spline-interpolated sampled signal is a pretty good approximation to the original. In cases where you care about detecting the values and/or locations of signal peaks, such as during spike sorting, performing spline interpolation can often improve accuracy substantially!
